

Current Research Topics 2026
Pretraining Large Language Models (LLMs)
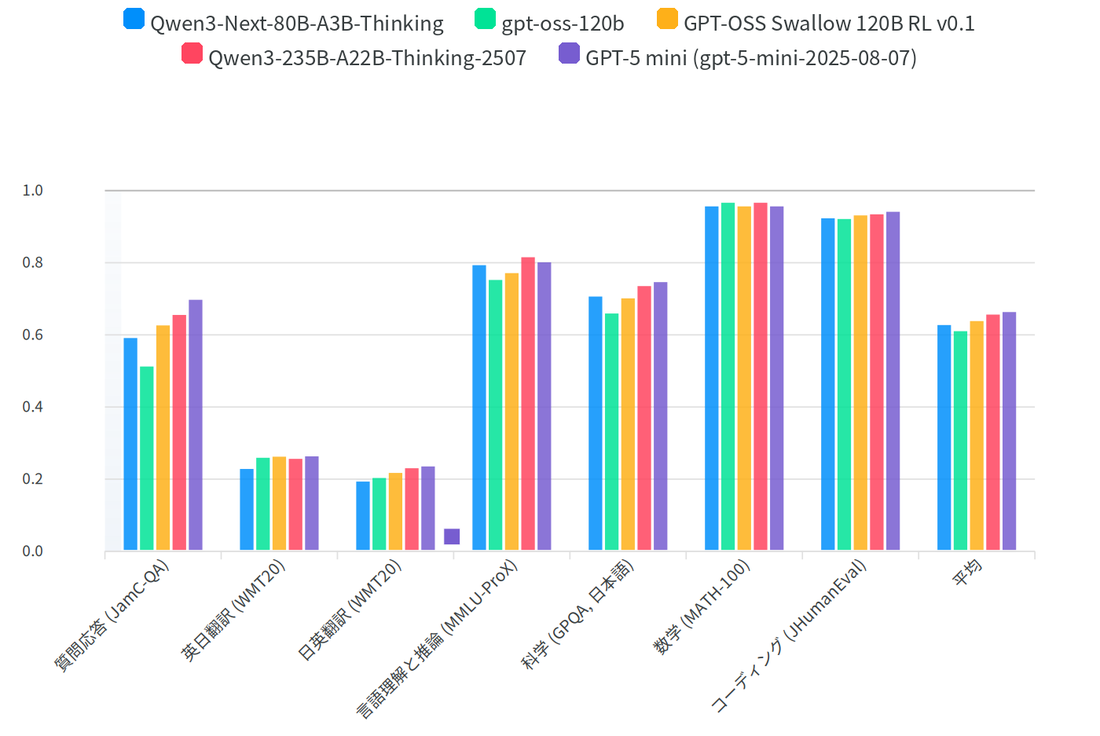
The Yokota Lab is developing the Japanese large language model Swallow in collaboration with the Okazaki Lab and AIST. Since pretraining from scratch requires a huge amount of computing resources, we perform continual pre-training on Japanese text starting from open models such as gpt-oss and Qwen3, which were trained mainly in English. The latest gpt-oss Swallow models (20B and 120B), released in February 2026, were built in three stages: continual pre-training on a 400-billion-token corpus that balances Japanese, English, mathematics, and coding (including Swallow Corpus v3.2 and the newly developed SwallowMath-v2 and SwallowCode-v2), supervised fine-tuning, and reinforcement learning with verifiable rewards (RLVR). Both models achieve top performance among open-weight LLMs of their size, with notable gains on mathematics and Japanese knowledge tasks. The model parameters are published on HuggingFace, so they can be used for research and commercial purposes. In contrast, the LLM-jp model developed at the NII LLM Research and Development Center is pre-trained from scratch in Japanese and English. In addition to the model parameters, we also publish the data used for training and also the failed cases.
▲Click image to enlarge
Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks — ICLR 2026 Oral
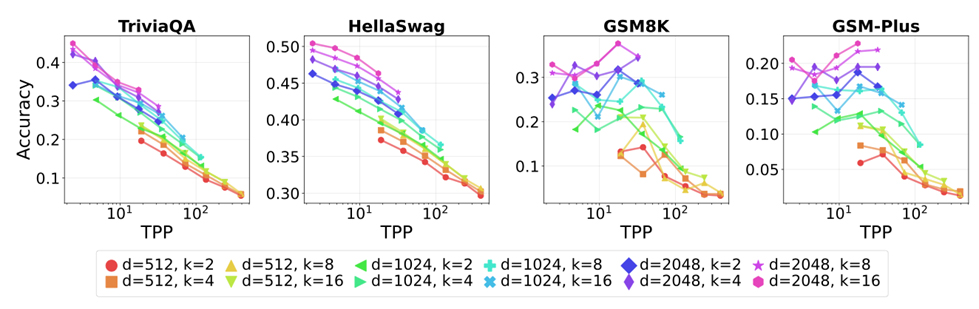
This work was accepted for Oral presentation at ICLR 2026. Empirical scaling laws have driven the evolution of large language models (LLMs), yet their coefficients shift whenever the model architecture or data pipeline changes. Mixture-of-Experts (MoE) models, now standard in state-of-the-art systems, introduce a new sparsity dimension that current dense-model frontiers overlook. We investigate how MoE sparsity influences two distinct capability regimes: memorization skills and reasoning skills. By training MoE families that vary total parameters, active parameters, and top-k routing under fixed compute budgets, we disentangle pre-training loss from downstream accuracy. Our results reveal two principles. First, Active FLOPs: models with identical training loss but greater active compute achieve higher reasoning accuracy. Second, Total tokens per parameter (TPP): memorization tasks improve with more parameters, while reasoning tasks benefit from optimal TPP, indicating that reasoning is data-hungry. Neither reinforcement learning post-training (GRPO) nor increased test-time compute alters these trends. We therefore argue that optimal MoE sparsity must be determined jointly by active FLOPs and TPP, revising the classical picture of compute-optimal scaling. Our model checkpoints, code and logs are open-source at https://github.com/rioyokotalab/optimal-sparsity.
▲Click image to enlarge
PowerCLIP: Powerset Alignment for Fine-Grained Contrastive Pre-Training (CVPR 2026)
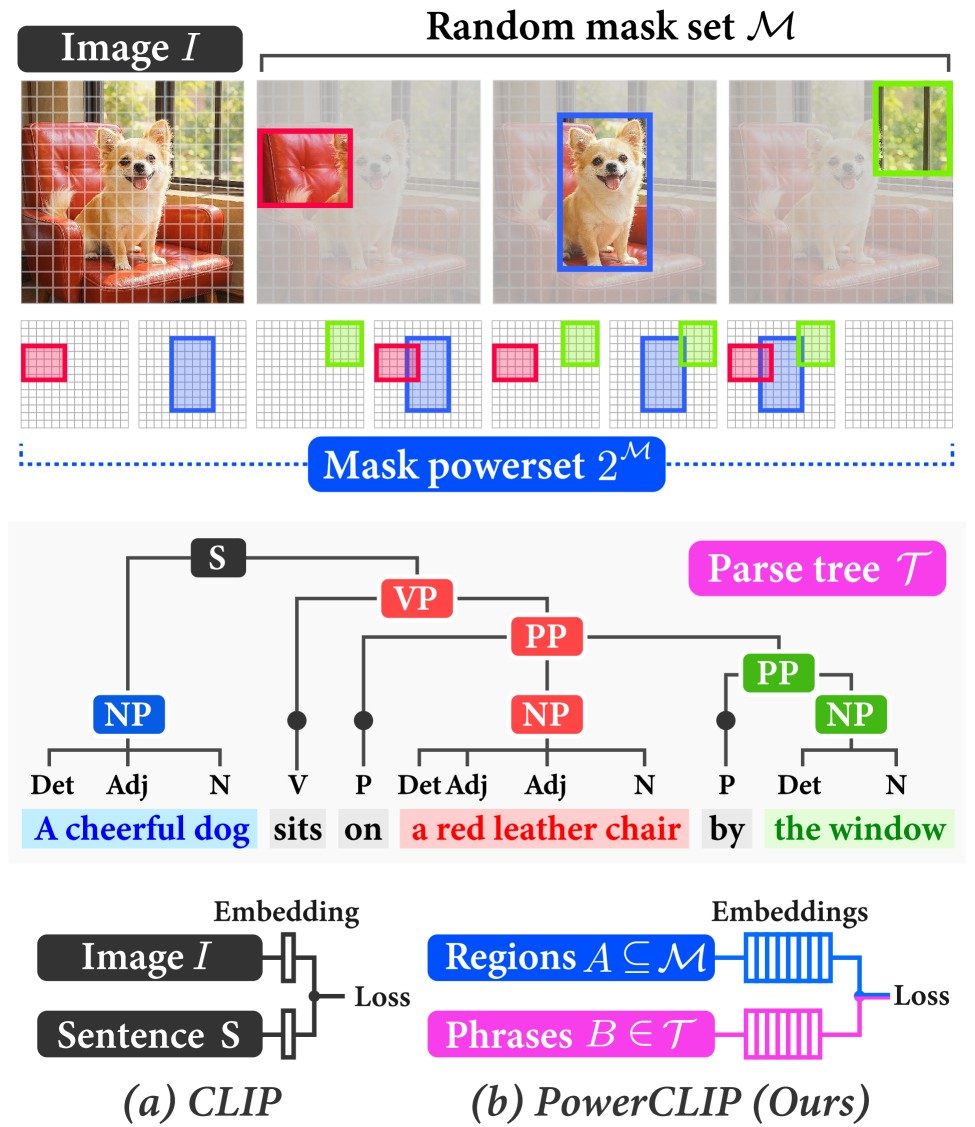
Contrastive vision-language pre-training frameworks such as CLIP have demonstrated impressive zero-shot performance across a range of vision-language tasks. Recent studies have shown that aligning individual text tokens with specific image patches or regions enhances fine-grained compositional understanding. However, it remains challenging to capture compositional semantics that span multiple image regions. To address this limitation, we propose PowerCLIP, a novel contrastive pre-training framework enhanced by powerset alignment, which exhaustively optimizes region-to-phrase alignments by minimizing the loss defined between powersets of image regions and textual parse trees. Since the naive powerset construction incurs exponential computational cost due to the combinatorial explosion in the number of region subsets, we introduce efficient non-linear aggregators (NLAs) that reduce complexity from O(2^M) to O(M) with respect to the number of regions M, while approximating the exact loss value with arbitrary precision. Our extensive experiments demonstrate that PowerCLIP outperforms state-of-the-art methods in zero-shot classification and retrieval tasks, underscoring the compositionality and robustness of our approach. This work was accepted to the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026, and the code is available on GitHub.
▲Click image to enlarge
Masked Gated Linear Unit
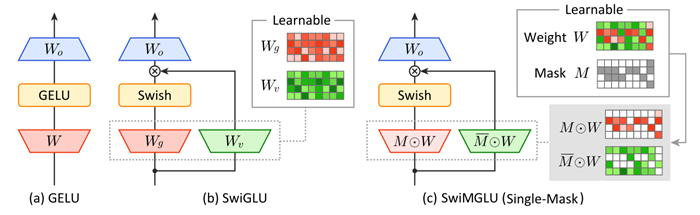
Gated Linear Units (GLUs) have become essential components in the feed-forward networks of state-of-the-art Large Language Models (LLMs). However, they require twice as many memory reads compared to feed-forward layers without gating, due to the use of separate weight matrices for the gate and value streams. To address this bottleneck, we introduce Masked Gated Linear Units (MGLUs), a novel family of GLUs with an efficient kernel implementation. The core contribution of MGLUs include: (1) the Mixture of Element-wise Gating (MoEG) architecture that learns multiple binary masks, each determining gate or value assignments at the element level on a single shared weight matrix resulting in reduced memory transfer, and (2) FlashMGLU, a hardware-friendly kernel that yields up to a 19.7 × inference-time speed-up over a naive PyTorch MGLU and is 47% more memory-efficient and 34% faster than standard GLUs despite added architectural complexity on an RTX5090 GPU. In LLM experiments, the Swish-activated variant SwiMGLU preserves its memory advantages while matching - or even surpassing - the downstream accuracy of the SwiGLU baseline.
▲Click image to enlarge
Thesis 2025
Design and Training of High-Performance Mixture-of-Experts Language Models under Fixed Computational Budgets(Taishi Nakamura)
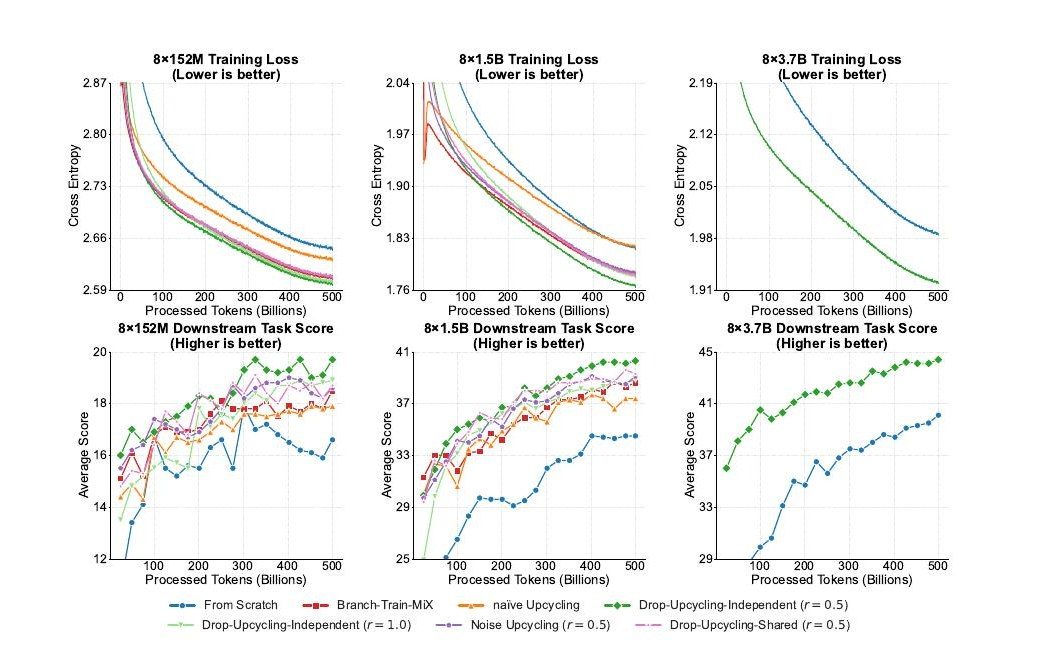
Recent advances in large language models (LLMs) have been driven by scaling laws that relate model size, data volume, and computational cost. While increasing model parameters generally improves performance, such scaling inevitably requires massive computational resources. The Mixture-of-Experts (MoE) architecture has emerged as a promising solution that achieves efficient scaling by activating only a subset of experts for each input. However, even MoE models remain computationally expensive to train, and methods for maximizing performance under fixed compute budgets are still underexplored. This thesis investigates how to design and train compute-efficient MoE language models through two complementary approaches: efficient initialization and architectural optimization. First, we propose Drop-Upcycling, a new training method that leverages pretrained dense models to accelerate MoE training while maintaining long-term convergence. Unlike naive upcycling, which simply replicates the dense feedforward layers across experts, Drop-Upcycling selectively re-initializes a fraction of expert parameters using statistical information from the original weights. This partial re-initialization promotes expert specialization while preserving transferable knowledge from the dense model. Large-scale experiments demonstrate that Drop-Upcycling resolves the trade-off between short-term knowledge transfer and long-term convergence speed. Specifically, an MoE model with 5.9 billion active parameters achieves comparable performance to a 13B dense model while using only one-quarter of the training FLOPs. Second, we conduct a systematic study on the architectural sparsity of MoE models to determine compute-optimal configurations. By varying the total number of experts, active parameters, and top-k routing, we evaluate reasoning and memorization tasks under identical compute budgets. The results reveal that performance is not monotonically improved by increasing sparsity; rather, there exists an optimal sparsity ratio depending on the task type. Reasoning tasks require a careful balance between active FLOPs and tokens per parameter (TPP), while memorization tasks benefit more from higher sparsity. Together, these results demonstrate that both initialization strategy and architectural design play critical roles in realizing efficient scaling, establishing practical guidelines for training high-performance sparse language models under limited computational resources.
▲Click image to enlarge
Development of Large Language Models for Long Contexts(Takumi Okamoto)
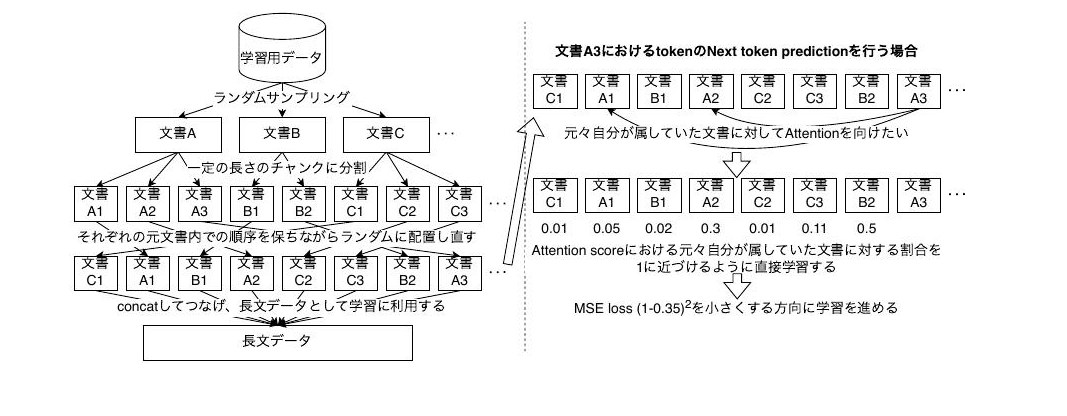
Large language models that can use long documents and conversation histories to generate answers have advanced rapidly, but several problems remain: increased memory requirements for training and inference, slower training and inference speeds, performance degradation as attention becomes diffuse over many tokens, and a shortage of training data for long-context models. To address the data shortage, prior work has proposed constructing long documents from short ones by chunking and reordering, creating pseudo long-range dependencies; training on such data improves long-context performance. However, no method has explicitly strengthened the exchange of information between dependent tokens, so it has not been clearly verified that the improvement actually comes from learning these pseudo long-range dependencies. This thesis adds a new loss function that encourages attention to tokens originating from the same source document when training on such data, to test whether explicitly learning pseudo long-range dependencies improves long-context performance. Evaluations on the HELMET and RULER benchmarks show improvements of up to 2.63 points (3.16%) in the summed averages compared to training without the additional loss, confirming that learning pseudo long-range dependencies is useful for long-context performance, although the gains vary by task. Applying the new loss to sparse attention yielded a more limited improvement of up to 0.82 points, indicating that further refinement is needed for practical use.
▲Click image to enlarge
Efficient Pre-Training of Large Language Models on Medical Data(Zhiyi Huang)
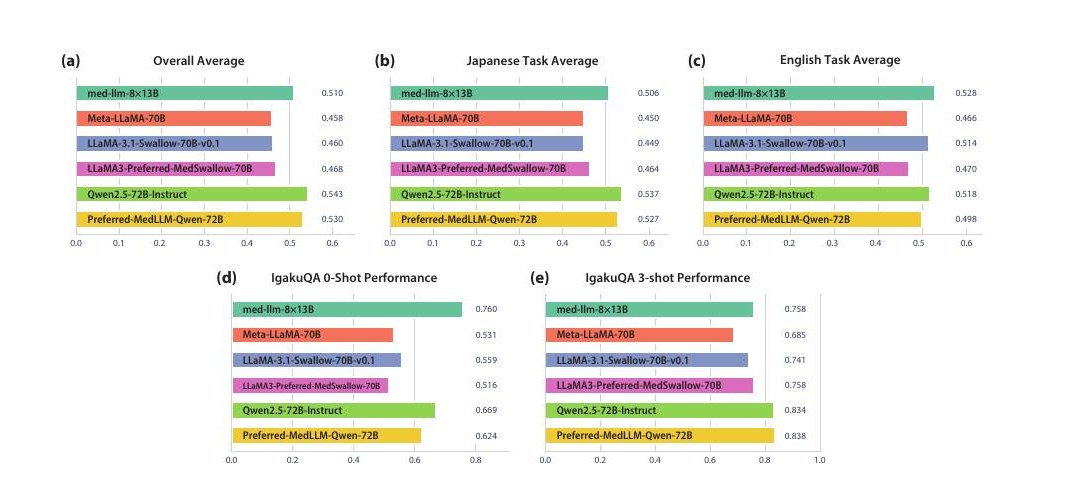
Large language models (LLMs) have pushed the boundary of artificial intelligence forward in most major fields since the release of ChatGPT, and researchers are also pushing LLMs into high-stakes domains such as medicine. Medicine is one of the most complex domains for AI use, as lives are at risk. There are many medical LLM releases already, and frontier models are somewhat sufficient for general medical consultation. But in Japan, where medical environments and equipment are largely different from those in the US and China, where the most commonly used models are developed, the models may lack knowledge about unique medical protocols, specialized equipment, and distinct regulatory frameworks. Furthermore, the use of closed-source models or those with undisclosed training data poses significant risks in clinical settings, as it precludes rigorous auditing for algorithmic bias and provides no guarantee of data privacy compliance. In this research, we aim to develop open LLMs that are more suitable for use in the Japanese medical context. We enrich their medical knowledge and deepen their understanding of the Japanese medical environment by continually pre-training models that are already strong in Japanese on a manually curated corpus with full transparency. To efficiently train LLMs with a large number of parameters, we set up 3D parallelism on an AWS cluster to facilitate scalable training and fine-tuning. The resulting models — med-llm-8×13B, an MoE LLM with 22B active parameters, and med-llm-13B — demonstrated favorable accuracy on benchmarks including the Japanese National Medical Examination. The 8×13B MoE model performed comparably to 70B-parameter open-weight models whose construction details remain non-transparent. This also represents the first case in the Japanese medical field where complete corpus details have been disclosed for fully from-scratch development.
▲Click image to enlarge
Tensor Core Acceleration of M2L Translations in the Fast Multipole Method for the Biot–Savart Kernel(Tomokazu Saito)
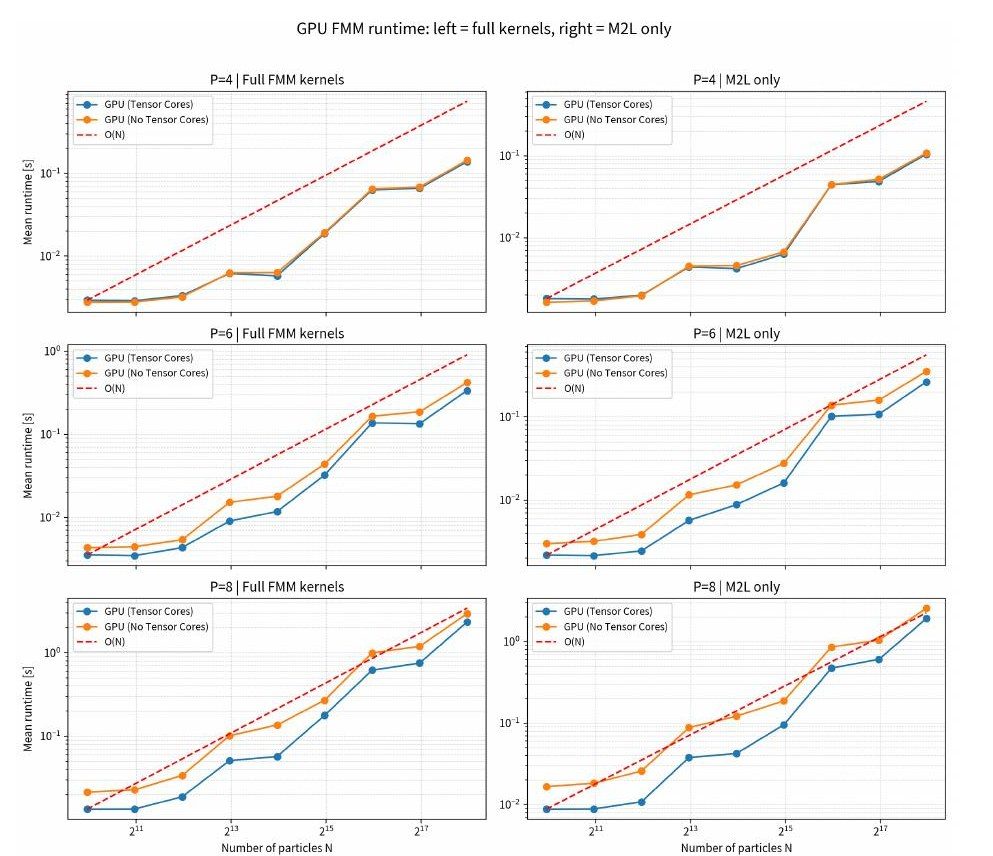
This thesis proposes, implements, and evaluates a method to accelerate the N-body computation of the Biot–Savart law, which dominates vorticity-field simulations such as vortex filament and vortex particle methods, by executing the M2L (Multipole-to-Local) translation — the core operation of the kernel-independent fast multipole method (KIFMM) — on GPU Tensor Cores. While the direct method requires O(N²) work, FMM/KIFMM hierarchically partitions space, computes near-field interactions directly, and evaluates far-field interactions as linear transformations between expansion coefficients, achieving nearly O(N) complexity. In practice, the M2L phase that handles far-field interactions between same-level cells tends to be the main bottleneck. Noting that KIFMM's M2L operators can be expressed as dense matrices of fixed shape for each relative cell position, we aggregate cell pairs by relative-position pattern, reformulate the computation as matrix–matrix products (GEMM), and execute it with the mixed-precision matrix engines of Tensor Cores, designing precomputed GPU-resident translation matrices, packed and padded input coefficients, and a batching scheme that avoids write conflicts. On an RTX 4090 with CUDA 12.8, computation time scales nearly O(N) with particle count, the relative error decreases exponentially with expansion order P (about 10⁻⁴ at P=5), and the M2L phase is substantially shortened by Tensor Cores. Compared with a 24-core Xeon Gold 5418Y CPU, the GPU is faster for large problems even without Tensor Cores, while small problems are limited by parallelism and PCIe transfers; the overall speedup is currently bounded by other phases such as P2P. For multi-GPU distributed parallelism, exchanging only small subtrees via the Local Essential Tree (LET) approach was measured to scale better than the Shift Bodies method.
▲Click image to enlarge
Bachelors Thesis 2025
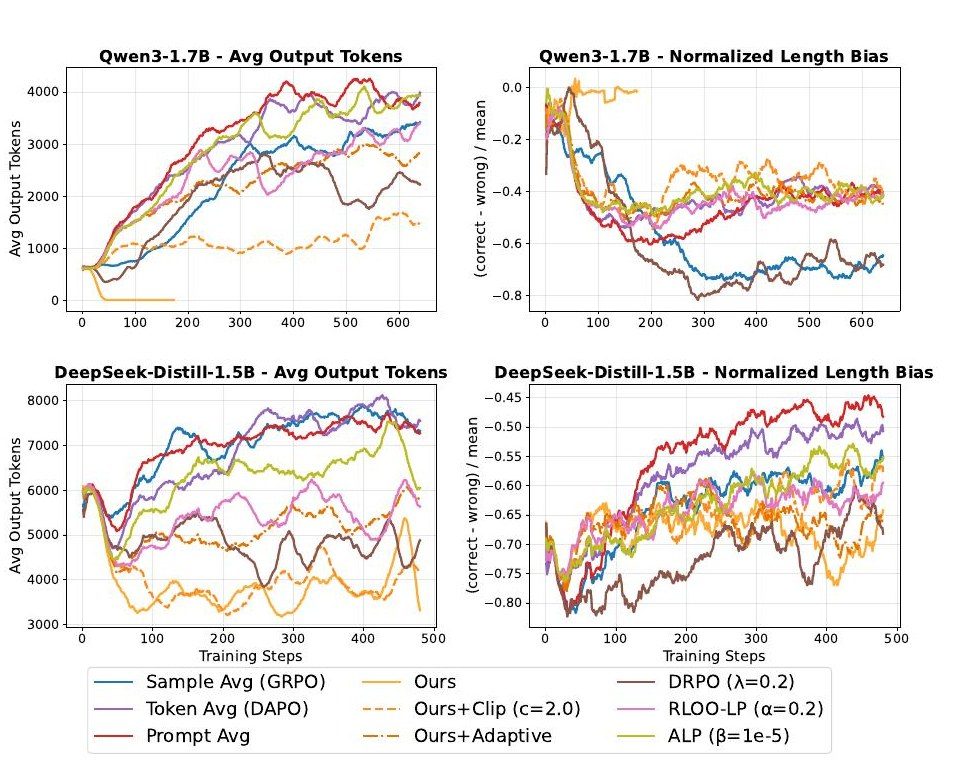
Efficient Logical Reasoning in Large Language Models via Reinforcement Learning(Daisuke Nohara)
Large language models (LLMs) have made remarkable progress in natural language processing and are expected to be applied to tasks requiring advanced reasoning, such as mathematical problem solving and code generation. Reinforcement learning with verifiable rewards (RLVR) combined with Group Relative Policy Optimization (GRPO) has attracted attention for improving reasoning ability, as demonstrated by DeepSeek-R1. However, models trained with RLVR and GRPO tend to produce verbose reasoning and ever longer outputs, which increases inference time and computational cost. This study focuses on the loss-aggregation scheme in the GRPO objective and proposes a method to shorten output length. Noting that differences in loss aggregation can be interpreted as different per-token weightings, the proposed method applies weights based on the inverse of output length to correct responses — reinforcing short correct answers more strongly — while treating all tokens of incorrect responses equally, thereby controlling output length purely through the design of the objective function, without introducing a length penalty into the reward. Experiments on mathematical reasoning tasks with Qwen3-1.7B-Base and DeepSeek-R1-Distill-Qwen-1.5B show that while output length keeps growing under existing loss-aggregation schemes, the proposed method mitigates this growth. With Qwen3-1.7B-Base, accuracy tended to increase with output length, suggesting that length penalties can hinder capability acquisition during reasoning training, whereas DeepSeek-R1-Distill-Qwen-1.5B achieved its best accuracy at moderate output lengths, where the proposed method shortened outputs while matching the performance of comparison methods. These results show that output length can be reduced through objective design alone, with an effect comparable to existing length-penalty methods, though without a clear performance advantage.
▲Click image to enlarge
Improving Japanese OCR Performance of Vision-Language Models(Shungo Yasuda)
With the rapid development of deep learning, vision-language models (VLMs) can handle more diverse and complex tasks than conventional CNN-based image recognition models. In optical character recognition (OCR), one of the tasks VLMs address, improving Japanese OCR performance requires large collections of document images written in Japanese. However, publicly available Japanese document datasets are limited, due to annotation costs and ethical constraints including copyright and confidentiality. This study addresses the problem by establishing a method to render document images from text while taking into account the layout structures characteristic of Japanese documents. Noise is further added to reproduce the visual characteristics of scanned real documents, aiming to stabilize recognition performance. Focusing on kanji recognition under low-resolution conditions — a particularly difficult problem in Japanese OCR — super-resolution is applied only to character regions judged difficult to recognize, and feeding the super-resolved images to the VLM as additional input is confirmed to improve OCR performance. These results show that the proposed approach can deliver meaningful improvements in VLM-based OCR even when large-scale datasets in a given language are unavailable.

▲Click image to enlarge
Thesis 2024
Pre-training of Visual-Language Models Using Synthetic Image Data(Yuji Iguchi)
In recent years, with the advancement of deep learning technology, visual-language models that simultaneously handle images and text have achieved remarkable results across diverse tasks. However, when using large-scale real image datasets, concerns about copyright, privacy, and ethical issues are always present. Furthermore, data collected from the internet may contain inappropriate content or biases, posing risks of negatively impacting model inference results and fairness. Therefore, this study proposes an approach to train CLIP, a prominent visual-language model, using artificial image data created via 3D simulation and automatically generated captions. Specifically, within the simulation platform TDW running on Unity, we controlled object placement, camera positions, and object materials across diverse scenes to artificially generate a large volume of images.
We then converted the parameter information from this process into text using a rule-based system to create captions. Using this artificial dataset for CLIP pre-training yielded noticeable learning effects in model fine-tuning and linear classification tasks, but failed to achieve zero-shot inference capability. This indicates that while acquiring broad-spectrum inference ability solely with current artificial datasets remains challenging, learning benefits were observed for specific tasks. Furthermore, this study systematically analyzed the impact of various factors on model performance during training with real datasets. These factors included caption length, the number of objects in an image, and the presence of a background. Experimental results revealed that model performance across downstream tasks varies significantly depending on task characteristics and data design. Notably, strategies to reduce data creation costs—such as using captions containing only nouns or simplified backgrounds—do not necessarily significantly impair learning performance. The findings of this research provide valuable insights into data design for training visual-language models. They also demonstrate the usefulness of artificial datasets created using 3D simulations as alternatives or supplements to real images, which often pose challenges from copyright and privacy perspectives. Future work is expected to realize safe visual-language models that combine advanced zero-shot performance with broad adaptability to various tasks. This can be achieved by designing simulations incorporating more diverse objects and devising learning strategies that integrate synthetic data with small real datasets.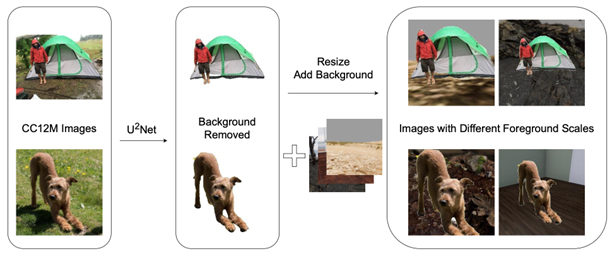
▲Click image to enlarge
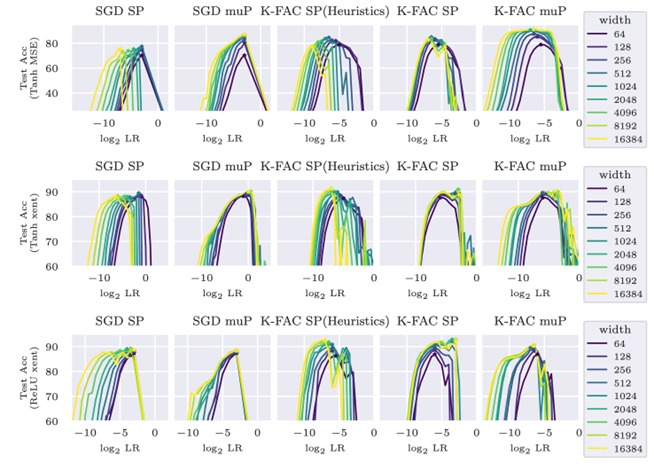
On the Stable Parameterization of Second-Order Optimization and Local Loss Optimization Effective Towards the Infinite Width(Satoki Ishikawa)
Second-order optimization has been developed to accelerate the training of deep neural networks and it is being applied to increasingly larger-scale models. In this study, towards training on further larger scales, we identify a specific parameterization for second-order optimization that promotes feature learning in a stable manner even if the network width increases significantly. Inspired by a maximal update parameterization (µP), we consider a one-step update of the gradient and reveal the appropriate scales of hyperparameters including random initialization, learning rates, and damping terms. Our approach covers two major second-order optimization algorithms, K-FAC and Shampoo, and we demon- strate that our parameterization achieves higher generalization performance in feature learning. In particular, it enables us to transfer the hyperparameters across models with different widths.
Next, we explored local learning, which trains a network through layer-wise local tar- gets and losses, and has been studied as an alternative to backpropagation (BP) in neural computation. However, its algorithms often become more complex or require additional hyperparameters because of the locality, making it challenging to identify desirable set- tings in which the algorithm progresses in a stable manner. To provide theoretical and quantitative insights, we introduce the µP in the infinite-width limit for two representative designs of local targets: predictive coding (PC) and target propagation (TP). We verified that ?P enables hyperparameter transfer across models of different widths. Furthermore, our analysis revealed unique and intriguing properties of ?P that are not present in con- ventional BP. By analyzing deep linear networks, we found that PC's gradients interpolate between first-order and Gauss-Newton-like gradients, depending on the parameterization. We demonstrate that, in specific standard settings, PC in the infinite-width limit behaves more similarly to the first-order gradient. For TP, even with the standard scaling of the last layer, which differs from classical µP, its local loss optimization favors the feature learning regime over the kernel regime.
▲Click image to enlarge
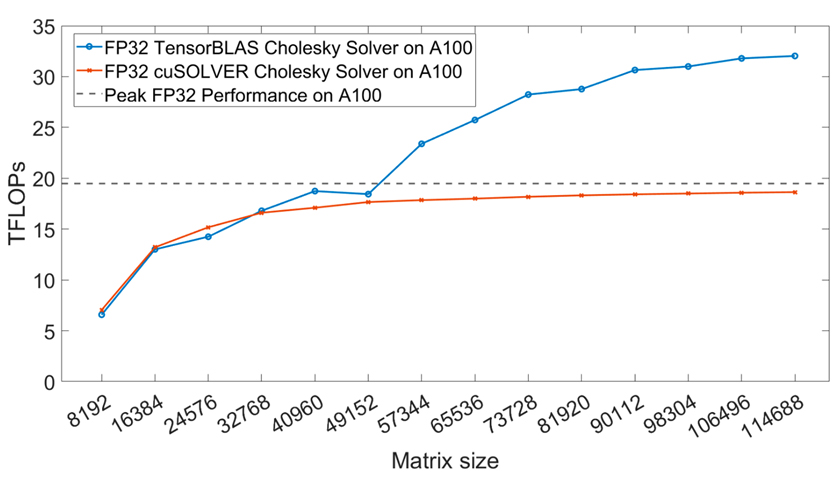
Accelerating Symmetric Rank-k Updates Using Tensor Cores(Runchu Zhao)
The BLAS3 library, which includes matrix-matrix multiplications and rank-k updates for general, symmetric, and triangular dense matrices, plays a crucial role in optimizing com- putational complexity in linear algebra. By exploiting the inherent structure of matrices, BLAS3 operations can significantly reduce the number of arithmetic operations required, making them essential for high-performance computing tasks in various fields such as sci- entific computing and machine learning. However, the rapid development of modern GPU architectures, such as those featuring Tensor Cores, introduces new challenges for exist- ing algorithms. These hardware units are optimized for fast low-precision General Matrix Multiply (GEMM) operations, but conventional algorithms often perform suboptimally on such hardware. This is particularly evident in the case of high-precision GEMMs, where mixed-precision accelerators like Tensor Cores can theoretically offer better performance but fail to fully leverage their potential with current BLAS libraries. To address these limitations, we propose a novel set of recursion-based BLAS3 algorithms that not only exploit the symmetric and triangular properties of matrices but also optimize data local- ity, enhance arithmetic intensity, and improve parallelism. These algorithms are designed to take full advantage of modern hardware features, specifically the high throughput of Tensor Cores, while minimizing computational overhead. Our approach contrasts with traditional recursive algorithms by using an iterative recursion-based strategy that priori- tizes data locality and increased arithmetic intensity-two crucial factors that contribute to performance gains in modern architectures. We experimentally evaluate the perfor- mance of our proposed TensorBLAS library, comparing it to Nvidia's cuBLAS library across a range of precision modes. On the A100 GPU, TensorBLAS achieves a speedup of up to 2.48x and 2.36x in FP16 and FP32 precision, respectively. On the RTX 4090 GPU, we observe an impressive speedup of up to 5.72x in FP64 precision. Furthermore, by lever- aging FP64 Tensor Cores, TensorBLAS outperforms cuBLAS with a nearly 1.5x speedup, demonstrating the superior efficiency of our methods. These results not only highlight the potential for significant performance improvements in linear algebra computations on modern GPUs, but they also pave the way for future advancements in high-performance computing, particularly in the areas of machine learning and large-scale scientific simula- tions. Our approach offers a promising solution to fully exploit the computational power of emerging hardware architectures, facilitating more efficient and scalable solutions for high-precision operations.
▲Click image to enlarge
Bachelors Thesis 2024
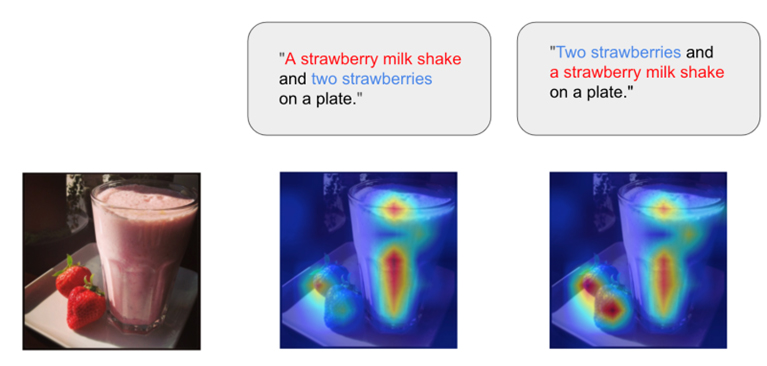
Training of CLIP Models Adapted to Word Order Shifts(Masaki Kawamura)
CLIP (Contrastive Language-Image Pretraining) has demonstrated high performance in multimodal learning between images and text and is also used as a foundation for Vision Language Models (VLM). However, numerous studies have pointed out challenges in its flexibility of linguistic representation and its ability for compositional reasoning. These challenges represent one of the most critical issues to overcome for expanding CLIP's application scope, significantly impacting real-world scenarios such as search systems, image generation, and visual question answering (VQA). Consequently, research to enhance CLIP's language understanding capabilities remains actively pursued. This study specifically focuses on a novel challenge: CLIP's excessive sensitivity to word order changes within captions. Specifically, the problem arises when CLIP outputs different recognition results for captions that have the same meaning but different word orders. This issue stems from a lack of linguistic flexibility and compositional reasoning capabilities, causing specific problems in CLIP's application domains. For example, in a search system, if a user inputs queries with different word orders or phrasing that convey the same meaning, CLIP may fail to understand them correctly, potentially leading to inconsistent delivery of expected search results. This research systematically identifies this unresolved challenge and proposes a novel approach to address it: expanding the diversity of captions in training data. Specifically, it achieves improved robustness to word order changes by introducing operations that rearrange word order or paraphrase while preserving caption meaning, and then training the CLIP model on this expanded data. As a result, we provide a new perspective on the challenge of compositional reasoning in CLIP, offer concrete guidelines for enhancing the flexibility of linguistic expression, broaden CLIP's applicability, and contribute to the further advancement of multimodal learning.
▲Click image to enlarge
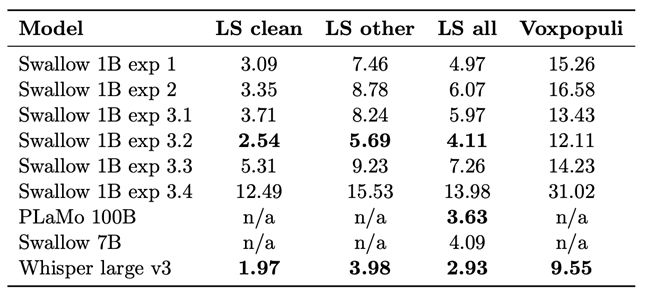
Building an Audio-Language Model Based on Large Language Models(Yukito Tajima)
Recent advancements in large language models (LLMs) have demonstrated exceptional capabilities in tackling complex linguistic tasks. However, their application to audio-language modeling remains an area of ongoing exploration. This thesis investigates the development of a Japanese audio-language model, leveraging open-source Japanese and English datasets. The study systematically examines the impact of various training strategies, including freezing components such as the encoder and decoder, to optimize performance in Japanese Character Error Rate (CER) and English Word Error Rate (WER) for automatic speech recognition tasks. The proposed audio-language model is built upon Whisper large v3 as the encoder and Llama 3.2 Swallow 1B as the language decoder. Experimental results reveal that training the decoder while freezing the encoder is the most effective strategy. This approach capitalizes on the robust pre-trained representations of the encoder while enabling the decoder to adapt to task-specific requirements. Notably, the model achieves a CER of 7.25 on JSUT and 5.94 on Common Voice v8.0, matching or surpassing the accuracy of Whisper. Moreover, this configuration delivers competitive performance across Japanese and English tasks, rivaling audio-language models with significantly larger decoders, including those with 100 billion parameters. Looking forward, addressing dataset quality issues is essential for further advancements. Integrating language model pre-training with audio data and scalirng the architecture to larger models, such as 8B or beyond, hold promise for improved generalization and performance. Future evaluations targeting domain-specific terminologies and specialized applications will provide deeper insights into the model’s real-world applicability. These efforts are expected to drive the development of robust and versatile audio-language models, advancing multilingual automatic speech recognition systems.
▲Click image to enlarge
Thesis 2023
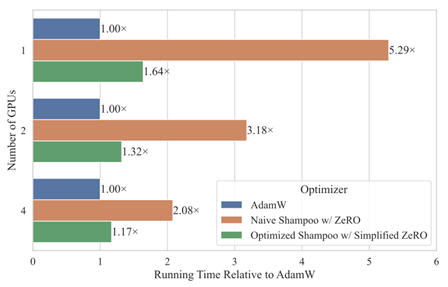
Development of Computationally Efficient Second-Order Optimizer for Large Language Models (Cong Bai)
In recent years, Large Language Models (LLMs) have garnered significant attention in the field of artificial intelligence due to their profound capabilities in understanding and generating natural language. However, the resource-intensive nature of training these huge models has led to monopolization by the tech giants, presenting a considerable bar- rier to progress within the field. Second-order optimizers, which leverage second-order information matrices such as Hessians, Fisher Information Matrices (FIMs) and gradient second moment matrices, hold promise for reducing the resources required for training by accelerating convergence. Yet, at the scale of deep learning, these second-order informa- tion matrices become impractically large. Although popular second-order optimizers like K-FAC and Shampoo have approximated these matrices, they still incur substantial over- head in language model training practice, forcing a compromise between tolerating this overhead and making further crude approximations, thereby hindering further research and application of them. This study aims at addressing this challenge and developing efficient second-order optimizers for training large language models.
▲Click image to enlarge
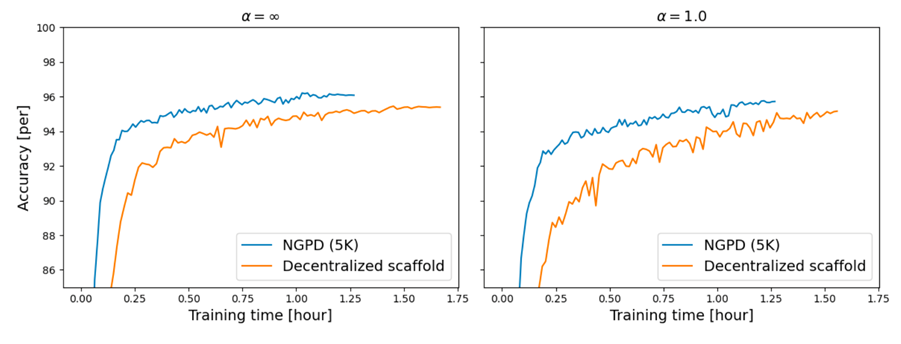
Distributed Learning Using the Natural Gradient Dual Method (Hiro Ishii)
In federated learning, a single model can be trained without collecting data from devices or servers, so even highly confidential data can be used for learning. In many cases, centralized federated learning is used, but distributed federated learning has also attracted attention in recent years due to its advantages of avoiding single points of failure and bottlenecks caused by the absence of a central server. However, the optimization method used in distributed cooperative learning is mainly a first-order optimization method that uses only the gradient, which results in excessive communication. In this study, we propose a new optimization method for distributed cooperative learning of deep neural networks, the Natural Gradient Primal Dual method (NGPD).
▲Click image to enlarge
Pretraining of Vision Transformers Using Synthetic Images (Shota Nakamura)
As the size of the pretraining data sets for deep vision models continues to increase, it is becoming increasingly difficult to filter problematic images in terms of copyright, privacy, and ethics. In fact, in December 2023, LAION.ai was forced to take down LAION5B, a large-scale image-text dataset, due to the presence of inappropriate images in the dataset. One approach to avoiding such problems from the outset is to use synthetic image datasets, which are generated based on mathematical formulas and do not use real images, for some of the pre-training. The quality of synthetic images as a pre-training dataset can be continuously improved by changing the generation method, but existing approaches require many rounds of trial and error based on human knowledge, and are very labor-intensive. In this study, we designed an indicator to predict the “quality of the pre-training dataset”, and automatically constructed a synthetic image dataset that is highly effective for pretraining vision transformers.
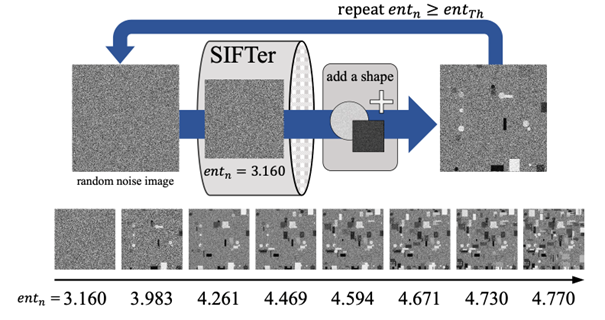
▲Click image to enlarge
Accelerating Allreduce in Large-scale Parallel Training on Fugaku (Shukai Nakamura)
In training large-scale deep learning models, we use distributed training methods such as data parallelism to speed up the training and model parallelism to divide the model. When training deep learning models on the supercomputer “Fugaku”, although the performance per node is inferior to other GPU machines, a method is used to achieve speed improvement by training using the large-scale node configuration of “Fugaku” and large-scale parallelization. However, deep learning using large-scale parallelization has the drawback that the ratio of communication time to training time increases, and could slow down the training. The aim of this research is to accelerate AllReduce on Fugaku. Considering its application to deep learning models, we divided the 6-dimensional torus direct network of Fugaku into three dimensions in three different parallel methods, and developed an AllReduce algorithm that can be used in each of these divisions.
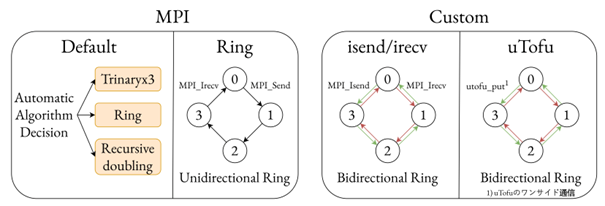
▲Click image to enlarge
Acceleration of Diffusion Models Training and Sampling Through the Use of Multiple Models (Zhaoqing Wang)
In recent years, Diffusion Probabilistic Models (Diffusion Models or DPMs) have sparked a surge in generative models for images. However, diffusion models still face challenges in terms of training and sampling efficiency. While various efforts have been made to accelerate sampling or enhance training strategies, these improvements are constrained by the limitations of the single-model backbone used in diffusion models. After a thorough examination of the theoretical foundations and existing analyses, we propose two approaches to enhance the efficiency of training and sampling in diffusion models. Firstly, we advocate separating a denoising model and a score model from the diffusion model backbone, training them with specific targets using only one inference. Secondly, we suggest unfolding the single-model backbone into multiple individual models and training them in a distributed manner.

▲Click image to enlarge
Bachelors Thesis 2023
Distributed Parallel Training of Large Language Models (Kazuki Fujii)
In recent years, various research institutions and companies have been developing large language models (LLMs). These models have attracted a great deal of attention for their ability to understand and generate language in a way that is similar to that of humans, and for their potential to be applied to a wide range of fields. Distributed parallel training is essential for the efficient training of large language models, and is an important factor that has a significant impact on training efficiency. However, in many cases, papers and technical reports mainly describe the performance of the model, the training corpus, and the model architecture, and the know-how regarding distributed parallel learning methods is not sufficiently shared. In addition, the optimal distributed training method depends greatly on the model size, model architecture, and training environment, and it is rare that the settings in a particular paper are optimal in all cases. In this study, we trained LLMs for multiple model sizes: 2.8B, 7B, 13B, 70B, and 175B. We pre-trained from scratch and also continually from a pre-trained model. We also trained a state space model, which is not a Transformer architecture.
▲Click image to enlarge
Development of a Multilingual Multiexpert Model Using Continuous Learning (Taishi Nakamura)
LLMs can solve many natural language processing tasks with 0-shot or few-shot learning by pre-training on large corpora without fine-tuning for each task. There is an increasing trend to develop LLM for non-English languages. There are still many challenges to develop models that can efficiently handle multiple languages and tasks. Despite the importance of learning to program in one's native language for non-English speakers, there are few models that support code generation in such languages. In this study, we developed a multilingual model by performing continuous pre-training using Japanese, English, Finnish, Vietnamese, Hindi, and code, based on starcoderplus, a model that was mainly trained using English and code.
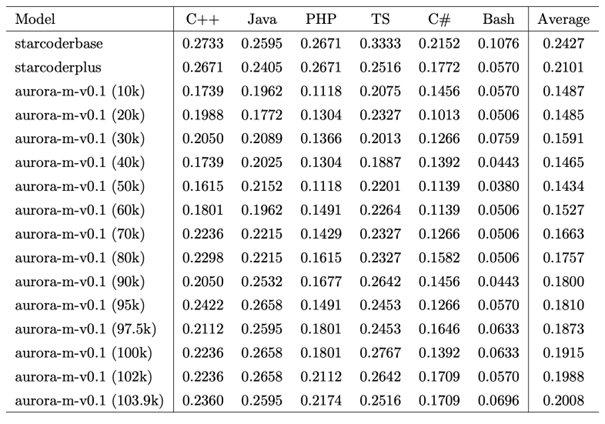
▲Click image to enlarge
Architecture Search for Large-Scale Language Models (Takumi Okamoto)
BERT is a model that appeared in 2018 and achieved SOTA in 11 NLP tasks at the time. However, because BERT uses a large model size and a large amount of pre-training data sets to achieve high performance, it takes a long time to train. To solve this problem, we use model compression, which reduces the model size while maintaining or improving performance by reducing the number of parameters used in the model and the number of bits used to represent each parameter. The proposed methods for model compression include pruning, quantization, distillation, low-rank matrix approximation, and Neural Architecture Search (NAS). Of these methods, although various search methods and search spaces have been proposed for models of visual tasks, there are few proposals for BERT and GPT. Therefore, in this study, we conducted an experiment to reduce the model size by using NAS to search for the optimal structure in BERT.
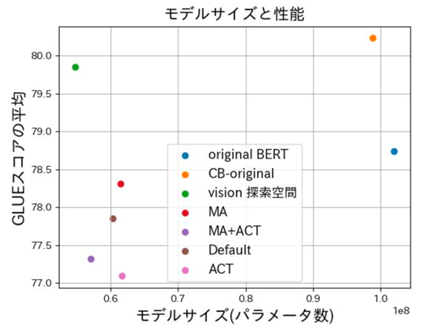
▲Click image to enlarge
Thesis 2022
Scaling up Pre-training with Synthetic Images (Sora Takashima)
In the context of image recognition tasks, the highest accuracy has been achieved by ViT pre-trained on very large real image datasets such as JFT-300M/3B. On the other hand, labeled real image datasets used for pre-training have many problems such as ethical and copyright issues, difficulties in collection and labeling, and oligopoly by some organizations, and it is difficult to control these problems by increasing the dataset size. In this study, we developed three hypotheses about the human-made image dataset for FDSL to pre-training ViT: 1) contours of objects in the image are important, 2) variations in image representation are important, and 3) scaling up can improve the pre-training effect. We constructed new datasets {ExFractalDB, RCDB, VisualAtom} to test each hypothesis, and conducted a comparative verification of the pre-training effect of each dataset.
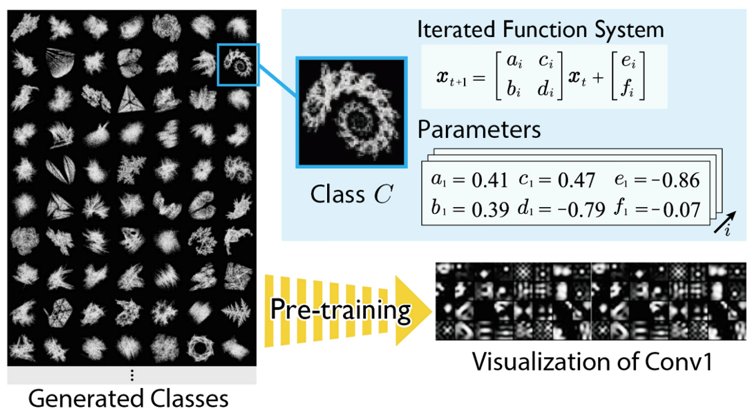
▲Click image to enlarge
Model Reduction Effect of NAS during Finetuning of Vision Transformers (Xinyu Zhang)
Vision Transformers (ViT), an application of Transformer used in natural language processing, have surpassed traditional Convolutional Neural Networks (CNN) in image classification on ImageNet by pre-training on large datasets. However, the models are becoming so large to achieve high accuracy that they cannot even fit on a single GPU, which limits their usefulness during inference. In order to reduce the size of such large ViT models while keeping their performance, we utilize Neural Architecture Search (NAS), which makes it possible to automatically design architectures of deep neural networks. We propose a method called Auto-MetaFormer, which can automatically search for architecture of MetaFormer based on algorithm of DARTS by Liu et al. It uses a gradient based approach to search for architecture by training architecture weights along with model weights. Auto-MetaFormer succeeds in automatically searching the MetaFormer architecture, gaining a 2% increase in accuracy using the same number of parameters. For the same classification accuracy, the number of parameters also be further reduced by 20% compared to the manually designed architecture.
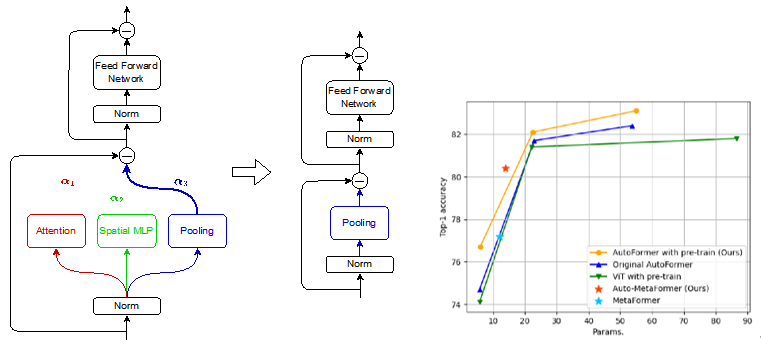
▲Click image to enlarge
Neural Network Pruning based on Second-Order Information (Sixue Wang)
Nowadays, deep learning has demonstrated its ability to solve arduous tasks in different domains, such as computer vision, voice interaction, and natural language processing, but there is a huge gap between academia and industry when considering cost, efficiency and quality. Neural network pruning is a common technique to reduce the size of neural networks. It selects some redundant parameters and removes them all. The goal of this thesis is to exploit second-order information in neural network pruning in a practical manner. We demonstrate that second-order neural network pruning can achieve better or comparable results within similar computational resources.
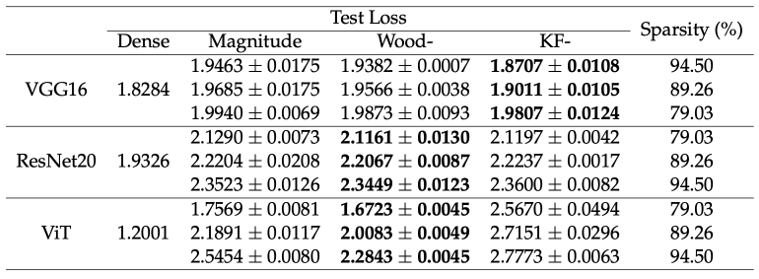
▲Click image to enlarge
Large-Scale Self-Supervised Learning of Driving Videos (Tomoya Takahashi)
In automated driving, recognition of the external environment obtained from cameras and lidar is the core of technology to ensure safety. Although the accuracy of these recognitions has been dramatically improved with the advent of deep learning, it is still not sufficient to realize fully automated driving. One of the reasons for this is that while a huge amount of vehicle driving data can be collected, the annotation cost of true-value labels is high, and it is difficult to prepare enough teacher data for learning. In this study, we aim to construct a recognition model that is robust to temporal changes in the visibility of objects by pre-training running videos using self-supervised learning on a pixel-by-pixel basis and by using optical flow. As a downstream task to evaluate the effect of the pre-training, we evaluated semantic segmentation using CityScapes. As a result, we found that accuracy varied greatly depending on the definition of neighborhood when comparing image pixels. In addition, we found that the accuracy can be further improved by using a mask to remove false positive examples, in which a pixel pair that is not originally a positive example is judged to be a positive example.
▲Click image to enlarge
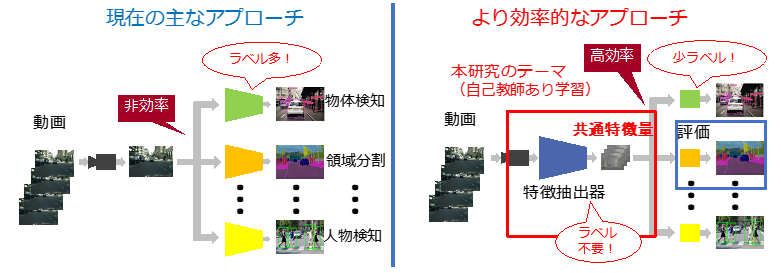
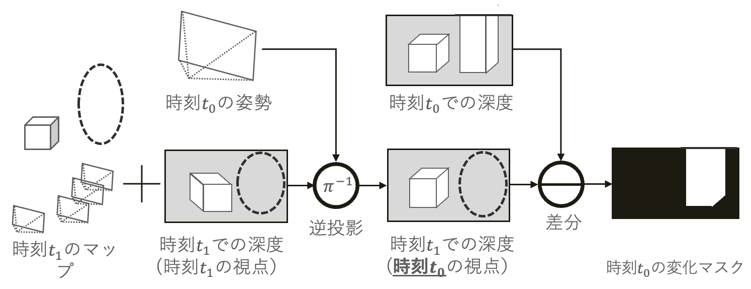
Change Detection by Visual SLAM Using Deep Learning (Kai Okawa)
Visual SLAM, which estimates the camera's self-position and reconstructs a 3D map of the surrounding area from a sequence of images, is one of the most important fundamental technologies in an AI society, playing the role of "eyes" in automated driving, AR/MR, and robotics. In recent years, methods capable of robustly estimating self-position and 3D maps in real time have emerged in Visual SLAM research. In addition, methods incorporating deep learning, which has evolved remarkably in recent years, have been proposed, enabling more accurate self-position estimation and 3D map restoration. However, after a certain period of time has passed since the 3D map was created, the actual scene may change, and discrepancies may arise between the 3D map and the actual scene. Such discrepancies degrade the accuracy of Visual SLAM and cause the 3D map to become bloated due to the accumulation of old information. In this study, we propose a change detection method for 3D maps at two different times, using information obtained from DROID-SLAM, which estimates a change mask using the dense depth information estimated by DROID-SLAM and the optical flow estimated by a regression-type neural network. In addition, a new change-aware objective function is introduced to optimize the change mask. Furthermore, a synthetic image dataset suitable for this study was created, and experiments were conducted. Through the experiments, we confirmed that it is possible to estimate the change mask for the two-time 3D map estimated by DROID-SLAM.
▲Click image to enlarge
Bachelors Thesis 2022
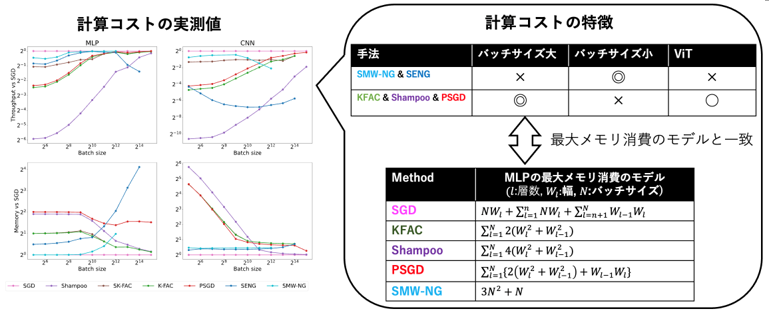
Gradient Preconditioning in Second-Order Optimization of Deep Learning (Satoki Ishikawa)
Gradient preconditioning using curvature matrices (Hessian matrix, Fisher information matrix, second-order moments) has become an important technique in a wide range of deep learning tasks. Gradient preconditioning is used in various domains, including second-order optimization to speed up deep learning optimization, continuous learning, branch-and-bound pruning, and Bayesian inference. In second-order optimization of deep learning, gradient preconditioning is performed after approximating the curvature matrix. Various types of approximation algorithms have been proposed for this purpose, but the differences in their characteristics have rarely been investigated. Therefore, this study compares these algorithms from two perspectives: computational aspects such as memory consumption and computation time, and training convergence. Since the overall learning time is determined by the product of the computation time per step and the number of steps required for convergence, it is very important to examine both of these characteristics. The results show that many second-order optimization methods, such as KFAC and Shampoo, have the potential to be particularly useful for learning at large batch sizes. We also found that second-order optimization methods such as SENG and SMW-NG, which use the SMW formula for the inverse matrix computation, have different properties than other methods.
▲Click image to enlarge
Pre-training of Vision Transformers Using Newton Fractals (Toshiki Omi)
In the field of image recognition, the mainstream method is to use a large-scale natural image dataset such as JFT-300M/3B for pre-training, followed by fine-tuning with the data of the target task. It is known that the larger the dataset used for pre-training, the higher the image classification and object recognition performance can be obtained, making the choice of which dataset to use for pre-training an important issue. However, natural image datasets pose many problems, including the collection of large numbers of images, labeling costs, copyright issues, content bias issues, and issues of fairness and offensive labels. In this study, we pre-trained the Vision Transformer Tiny model using an image dataset consisting of Newton Fractal images generated by the Newton method, and evaluated the performance of the dataset by the accuracy of the fine tuning task of CIFAR-10/100. The performance of the dataset was evaluated by the accuracy of CIFAR-10/100 fine tuning task. In addition, we conducted similar experiments on FractalDB and ExFractalDB, which are the conventional fractal datasets, and ImageNet, which is a natural image dataset, to compare the performance of the conventional method. As a result, the pre-training effect of the Newton Fractal image dataset was confirmed. As with the conventional FDSL dataset, the performance of the dataset consisting of black-and-white images was higher than that of color or grayscale images, and the performance was improved by changing the image generation conditions. Although the pre-training effect was lower than that of ImageNet, the pre-training effect was higher than that of the image representations used in conventional FDSL methods.

▲Click image to enlarge
Accelerating Quantum Vortex Simulations with Fast Multipole Methods (Tomokazu Saito)
Fluids at cryogenic temperatures have zero viscosity due to quantum effects. Such fluids are called superfluids. The physical properties of superfluids are important from an engineering viewpoint, but for applications, it is necessary to elucidate complex phenomena such as turbulence in superfluids. However, experiments on superfluids require expensive equipment because the fluid must be maintained at extremely low temperatures. Therefore, it is important to analyze the behavior of turbulence by simulation. However, methods that require a very fine mesh, such as the finite element method, require an enormous amount of time. Quantum turbulence is am inviscid fluid consisting of many vortex threads, and it is effective to use the Vortex Method. In this study, FMM, which calculates the interaction between vortex particles based on the Biot-Savart law, was implemented on CPUs and GPUs, and its calculation speed and accuracy were evaluated. However, we were able to confirm that the error decreases with increasing P in the implementation. Furthermore, we confirmed that the error converges to a constant value around 274 periodic images when the number of particles is 104 and the order of FMM is P = 10, while FMM can calculate periodic boundary conditions with minimum overhead.

▲Click image to enlarge
Thesis 2021
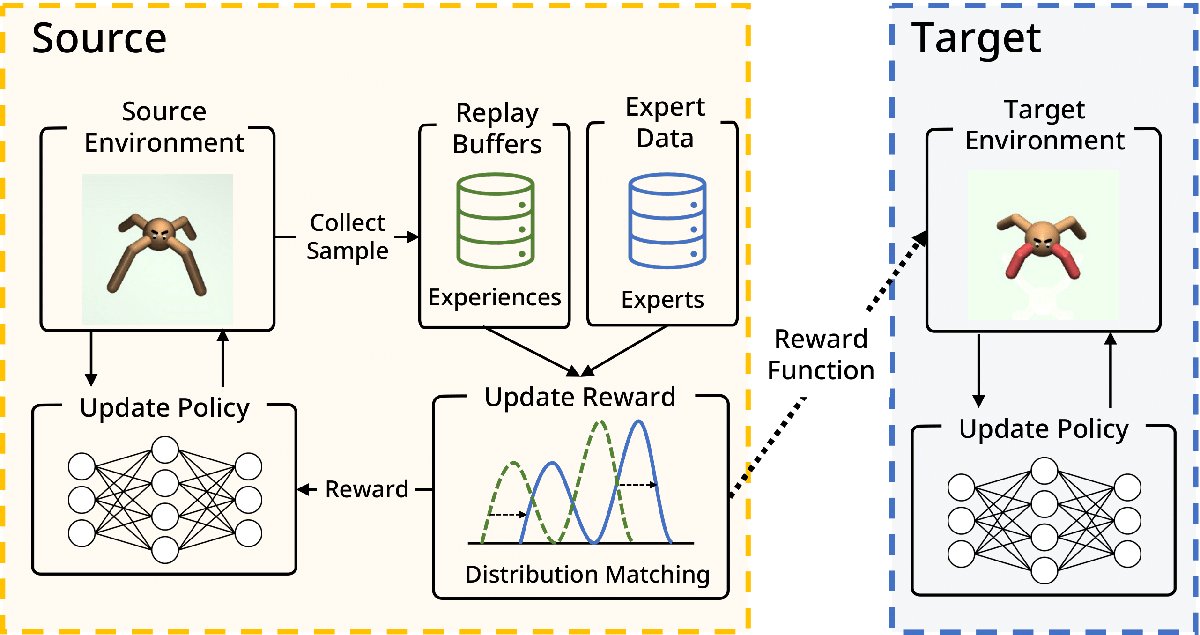
Off-Policy Inverse Reinforcement Learning via Distribution Matching (Hana Hoshino)
Inverse Reinforcement Learning (IRL) is attractive in scenarios where reward engineering can be tedious. However, prior IRL algorithms use on-policy transitions, which require intensive sampling from the current policy for stable and optimal performance. This limits IRL applications in the real world, where environment interactions can become highly expensive. To tackle this problem, we present Off-Policy Inverse Reinforcement Learning (OPIRL), which (1) adopts off-policy data distribution instead of on-policy and enables significant reduction of the number of interactions with the environment, (2) learns a reward function that is transferable with high generalization capabilities on changing dynamics, and (3) leverages mode-covering behavior for faster convergence. We demonstrate that our method is considerably more sample efficient and generalizes to novel environments through the experiments. Our method achieves better or comparable results on policy performance baselines with significantly fewer interactions. Furthermore, we empirically show that the recovered reward function generalizes to different tasks where prior arts are prone to fail.
▲Click image to enlarge
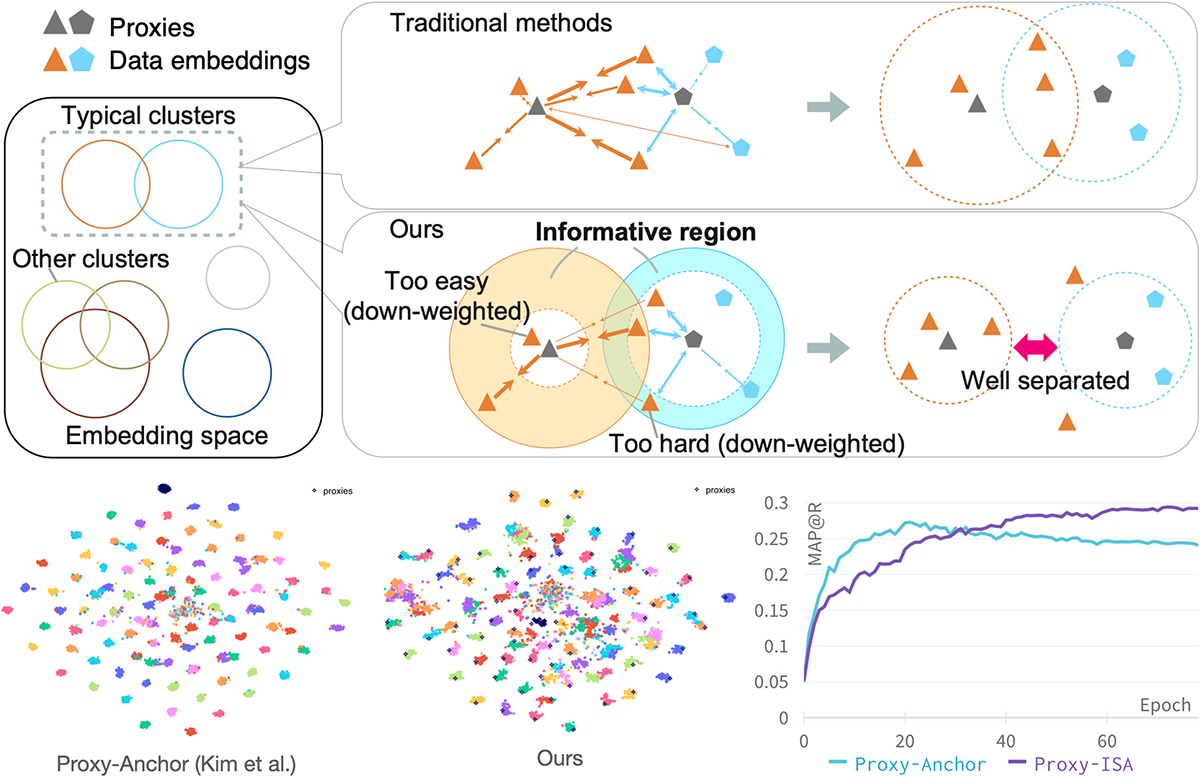
Informative Sample-Aware Proxy for Deep Metric Learning (Aoyu Li)
Metric Learning is one if the core fundamental tasks of machine learning. In deep metric learning (DML), the proxy-based methods are drawing more and more attention recently because of their flexibility and efficiency while maintaining higher performance. In this work, we propose a novel proxy-based method combined with class-dependent dynamic weighting, called Informative Sample-Aware Proxy (Proxy-ISA).
Proxies, which are class-representative points in the representation space, receive updates based on proxy-sample similarities as sample representations do. In existing methods, it may be possible that a relatively small number of samples producing large gradient magnitudes (i.e., hard samples) and a relatively large number of samples producing small gradient magnitudes (i.e., easy samples) play a major part in the update. Based on the assumption that acquiring too much sensitivities to such extreme sets of samples would deteriorate the generalization ability, the proposed Proxy-ISA directly modifies a gradient weighting factor to each sample. In this work, we first design a method to estimate the learned class-related region to acquire the information of class hardness. By defining the hard and easy samples adaptively to the class hardness, each proxy identifies its own hard and easy samples and reduces their weighting factors with a scheduled threshold function, so that the model acquires more sensitivity to the intermediate samples, which is called "informative" samples. Furthermore, we incorporate the idea of active learning to emphasize the informative samples dynamically according to the learning step, and the dynamic weights are assigned separately for positive pairs and negative pairs. Extensive experiments on the CUB-200-2011, Cars-196, Stanford Online Products and In-shop Clothes Retrieval datasets demonstrate superiority of Proxy-ISA over the state-of-the-art methods.
▲Click image to enlarge
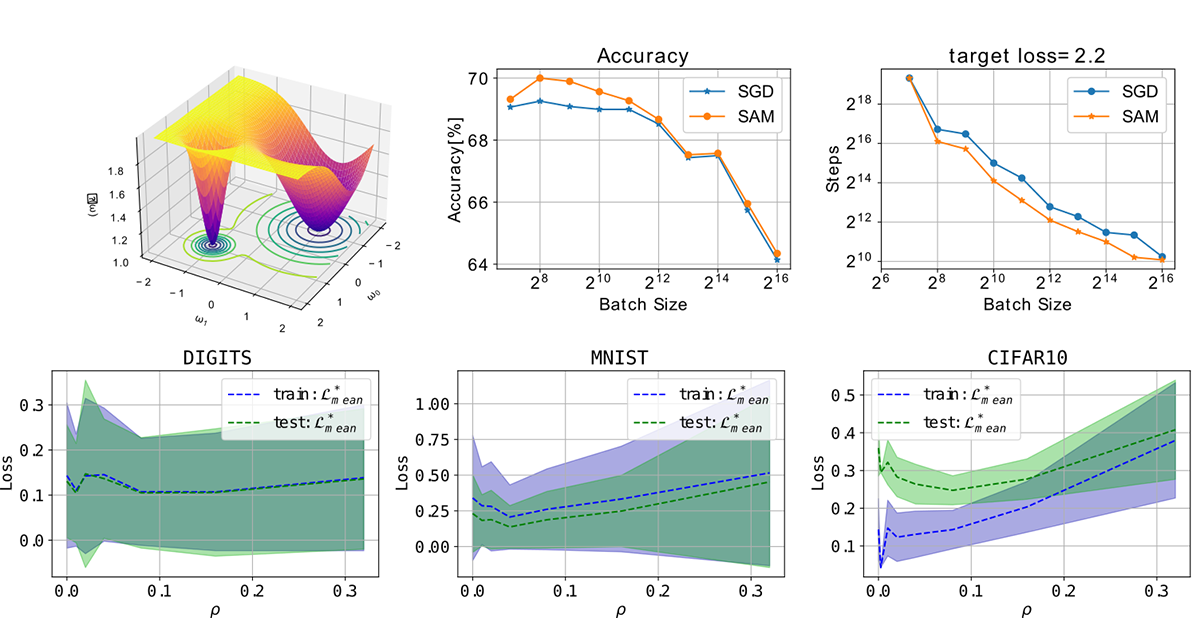
On the generalization gap of SAM optimizers for very large batch sizes (Elvin Munoz)
The generalization properties of a trained network are highly tied to the geometrical shape of the loss function evaluated at the parameters of the model; it has been found that flat minima increase the generalization properties of a neural network. Due to the stochasticity of most optimizers such as SGD, normally a flat minima will be found rather than a sharp minima. However, as we increase the batch size and thus reduce the stochasticity of the training process, it becomes more likely to fall into a sharp minima. There have been many methods that have been devised to counteract this effect and obtain high generalization properties even when using large batches, one of such methods is SAM (Sharpness-aware minimization). This method has been proven to improve the generalization properties of trained neural networks in the small-mid range of batch sizes and even it has been found to work in distributed training. However, a more in-detail study of its capabilities at higher batch sizes is needed; moreover this method introduces a new hyperparameter (neighborhood size) that needs to be tuned. The main goal of this work was to shed some light at the behavior of this optimizer when using a large batch (reaching almost full batch) and a study of the behavior of the neighborhood size for proper tuning.
▲Click image to enlarge
Thesis 2020
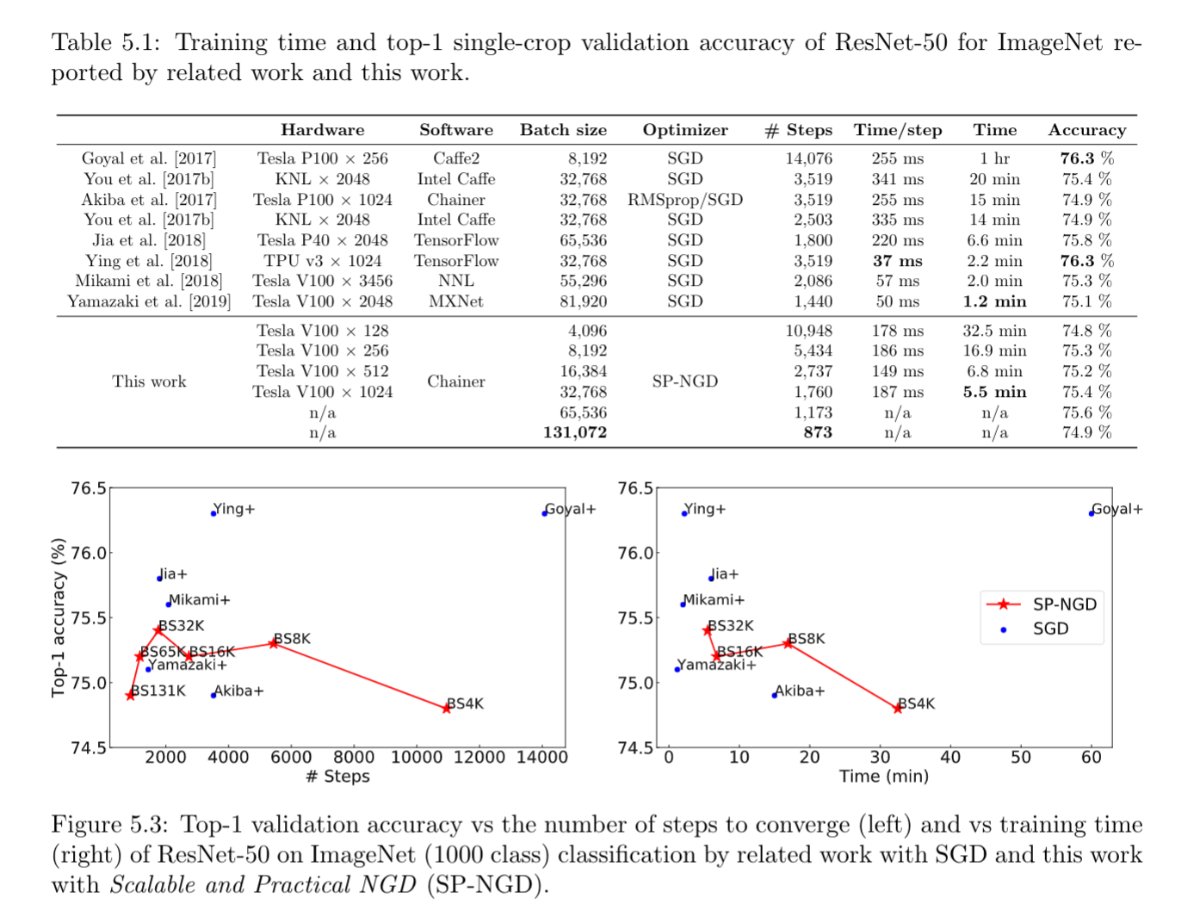
Second-order Optimization for Large-scale Deep Learning(Kazuki Osawa)
Large-scale distributed training of deep neural networks results in models with worse generalization performance as a result of the increase in the effective mini-batch size. Previous approaches attempt to address this problem by varying the learning rate and batch size over epochs and layers, or ad hoc modifications of Batch Normalization. We propose Scalable and Practical Natural Gradient Descent , a principled approach for training models that allows them to attain similar generalization performance to models trained with first-order optimization methods, but with accelerated convergence. Furthermore, SP-NGD scales to large mini-batch sizes with a negligible computational overhead as compared to first-order methods. We evaluate SP-NGD on a benchmark task where highly optimized first-order methods are available as references: training a ResNet-50 model for image classification on the ImageNet dataset. We demonstrate convergence to a top-1 validation accuracy of 75.4% in 5.5 minutes using a mini-batch size of 32,768 with 1,024 GPUs, as well as an accuracy of 74.9% with an extremely large mini-batch size of 131,072 in 873 steps of SP-NGD.
▲Click image to enlarge
Thesis 2019
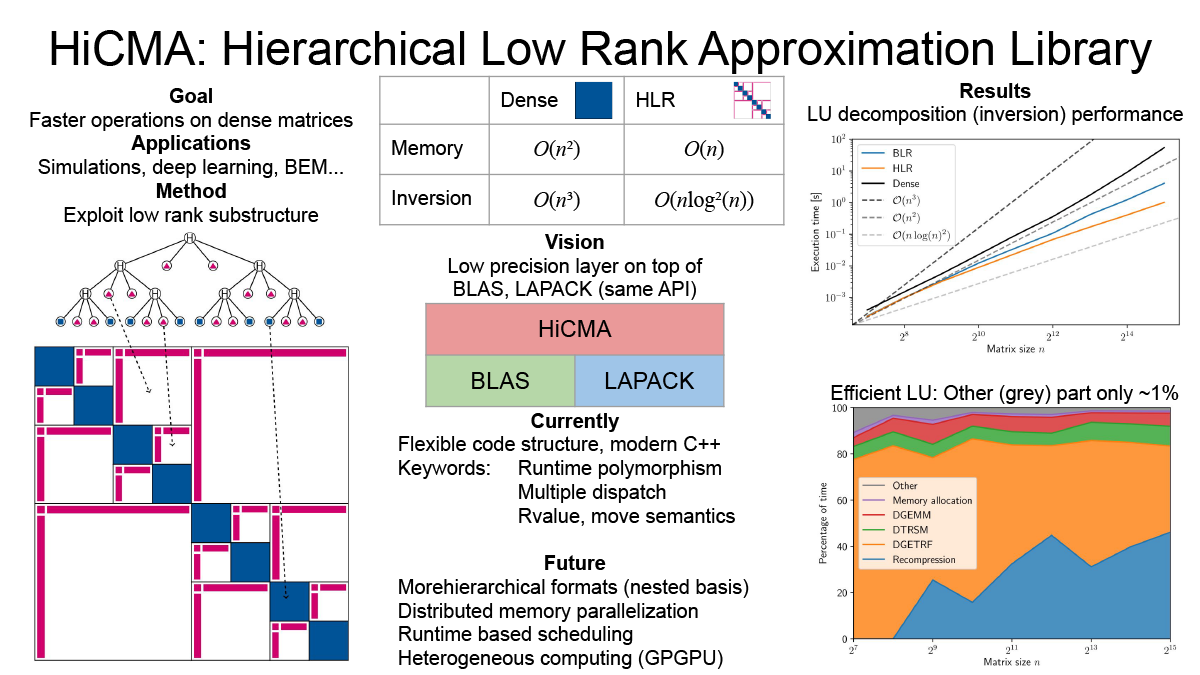
Efficient library for hierarchical low rank approximation (Peter Spalthoff)
Dense matrices have a quadratic memory complexity and many operations on them have cubic scaling. This makes them prohibitively expensive for large scale operations. In many applications (covariance matrices, BEM...) a substructure of low rank blocks is found. This substructure can be exploited to create an efficient compression of the matrix, called hierarchical low rank approximation. On the resulting so-called Hierarchical Matrices, which only have linear storage complexity, all arithmetic operations (multiplication, inversion...) can be defined. These operations are also much faster with cloes to linear complexity. We are working on a modern, flexible library with distributed memory parallelization on heterogeneous nodes.
▲ Click image to enlarge
Thesis 2018
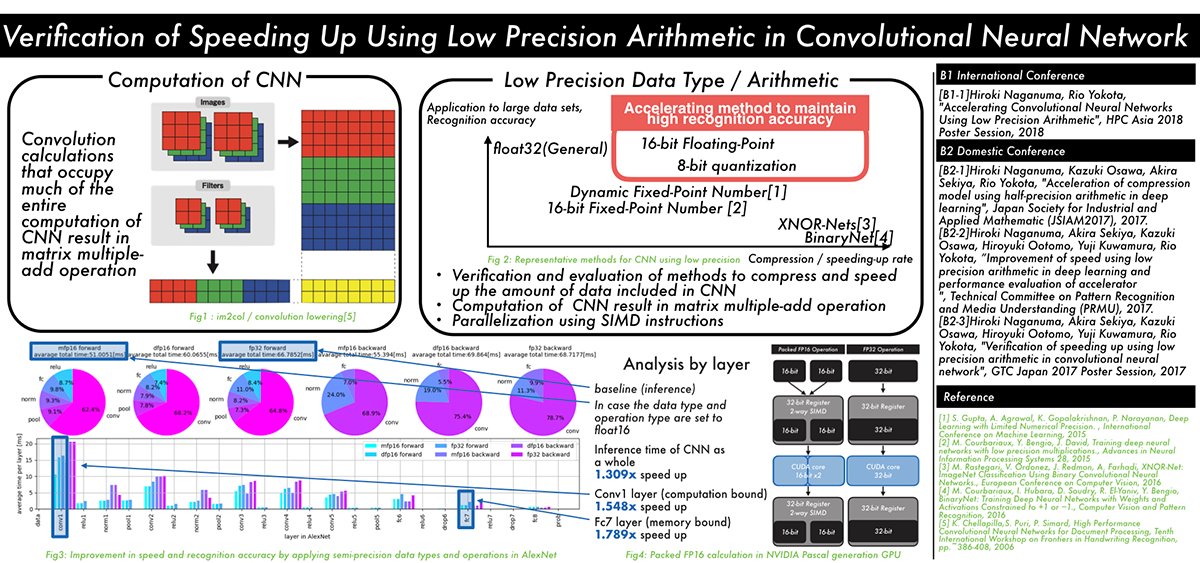
Verification of speeding up using low precision arithmetic in convolutional neural network (Hiroki Naganuma)
The recent trend in convolutional neural networks (CNN) is to have deeper multilayered structures. While this improves the accuracy of the model, the amount of computation and the amount of data involved in learning and inference increases. In order to solve this problem, several techniques have been proposed to reduce the amount of data and the amount of computation by lowering the numerical precision of computation and data by utilizing the CNN's resistance to noise.
However, there is a lack of discussion on the relationship between parameter compression and speedup within each layer of the CNN.
In this research, we propose a method to speed up the inference by using half precision floating point SIMD instructions, by applying low precision to the learned model, in addition to reducing the data of the CNN model, and speeding up data access for layers that are computation-bound.
We examined the influence of CNN recognition accuracy, the speedup for each layer, and its reason, when we apply our method.
▲ Click image to enlarge
Smoothing of the Objective Function in Stochastic Optimization for Large Scale Parallel Deep Learning (Hiroki Naganuma)
Classical learning theory states that when the number of parameters of the model is too large compared to the data, the model will overfit and the generalization performance deteriorates. However, it has been empirically shown that deep neural networks (DNN) can achieve high generalization capability by training with extremely large amount of data and model parameters, which exceeds the predictions of classical learning theory. One drawback of this is that training of DNN requires enormous calculation time. Therefore, it is necessary to reduce the training time through large scale parallelization. Straightforward data-parallelization of DNN degrades convergence and generalization. In the present work, we investigate the possibility of using second order methods to solve this generalization gap in large-batch training. This is motivated by our observation that each mini-batch becomes more statistically stable, and thus the effect of considering the curvature plays a more important role in large-batch training. We have also found that naively adapting the natural gradient method causes the generalization performance to deteriorate further due to the lack of regularization capability. We propose an improved second order method by smoothing the loss function, which allows second order methods to generalize as well as mini-batch SGD.

▲ Click image to enlarge